Works on My Machines
When I first tried Claude Code web agents, I was struck by the premise that I could literally code from my phone. I think it was Replit that first tried to seriously execute mobile coding (circa 2019), but no matter how ergonomic they made the editor UX, it was still tedious and clunky — mobile keyboards and voice input will never match the speed and fidelity of typing on a desktop. It took something like AI to make mobile coding possible, because AI changes the nature of what "coding on your phone" actually entails.
I broke my laptop recently, and had a similarly revelatory experience when I figured out I could set up a Digital Ocean VM and program on it remotely, via my phone, while I waited for a new Mac to arrive. Claude Web Agents are powerful, but their workflow is still constrained to a specific branch on a specific repo — too limited for a full stopgap Mac replacement — so I took this as an exercise to see how far I could get with a VM and an ssh terminal.
I would have never tried this before because typing up commands on my phone via ssh just wasn't going to happen. But a quick brew install claude lets me bypass all that; I simply told Claude to do the rest for me. "Claude set up Tailscale", "Claude clone this repo", "Claude fix this bug". I probably compressed the amount of characters I had to type by a factor of 10,000.
Coding on your phone still has limitations — it's a headline marketing feature more than a true UX shift. I'm not claiming that this is some glimpse into where the world is going, but it's certainly nice to code from your phone. I want to code from my phone in the same manner that I'd want to write emails from my phone — not often, as it's more cumbersome than a laptop; but sometimes, as it's way more convenient.
The more mundane, yet more powerful, idea that this points toward is that agents just need a computer to do their work. That can be your own computer…or it could be some random machine in the cloud, where it can run non-stop, unencumbered by the limitations of your local machine. The computer doesn't need to be super high-powered either, all it truly needs is a file system and a terminal.
Claude and Codex have taken a full hybrid approach to agent development — local and cloud, with seamless handoff between them. That makes perfect sense for current model capabilities and development workflows. Each task is an extension of the developer, so the developer must be able to pull that task back onto their machine to review, test, and fiddle with it manually if it isn't completely correct. Yet I can't imagine this is the stable end-state of development workflows. What will things look like when one human can supervise dozens of agents working on separate tasks? They won't be managing concurrent Claude Code sessions on their Mac. Each session competes for resources and shared file state, and stops working as soon as you close your laptop. Laptops were made for humans to do work during their workdays, not for agents to churn out code around the clock.
There are several reasons why I think cloud-based development will become the default:
- It's sandboxed — Local-first agent development is risky. Running in a VM allows for isolation in case the agent screws up the filesystem. Network policies prevent it from making rogue requests.
- It's highly parallel — Local-first development assumes that developers will intermediate agent workflows. As agents become more capable and prolific, running on one machine is a bottleneck.
- It's universally accessible — you can clone a repository and start working from anywhere. Code from your phone or your iPad. You can even collaborate on a session with coworkers.
The balance of power between local and server-side compute, "thick clients" vs "thin clients", has been oscillating since the beginning of the tech industry. Ben Thompson wrote a recent piece in Stratechery arguing that AI has driven computing back into a thin client era, where computers mostly act as simple interfaces to computation (i.e. inference) running elsewhere. He notes:
This is even clearer when you consider the next big wave of AI: agents. The point of an agent is not to use the computer for you; it's to accomplish a specific task. Everything between the request and the result, at least in theory, should be invisible to the user. This is the concept of a thin client taken to the absolute extreme: it's not just that you don't need any local compute to get an answer from a chatbot; you don't need any local compute to accomplish real work. The AI on the server does it all.
Thompson is right if you strictly consider humans as end-users, but thick clients aren't really going away. His "AI on the server" is not some opaque black box, it's just an AI with its own thick client, over which it has full domain — editing files, running local processes, executing whatever a human developer might on their laptop. [1]
Building "Cloude Code"
I started working on Cloude Code (pun intended) as a toy project, with no particular vision for it. I was inspired by Claude web agents, I wanted to try out Fly.io Sprites (a new VM sandbox product), and I'd recently read Ramp's blog post about their own internal coding agent, so I decided to build my own version of a cloud agent product. It didn't take long after starting to develop a sense for the important problems.
I'm often amused at how quickly you can jump to the frontier of this space. Thomas Ptacek points this out in his blog post:
I'm used to spaces of open engineering problems that aren't amenable to individual noodling. Reliable multicast. Static program analysis. Post-quantum key exchange. So I'll own it up front that I'm a bit hypnotized by open problems that, like it or not, are now central to our industry and are, simultaneously, likely to be resolved in someone's basement. It'd be one thing if exploring these ideas required a serious commitment of time and material. But each productive iteration in designing these kinds of systems is the work of 30 minutes.
That said, I'm not under any delusion about the competitive dynamics; if I can solve this in my basement then so can anyone else. That's why there are like 500 companies building agent orchestration products right now. The biggest companies in AI (Claude, Codex, Cursor) are all building some form of this product! But at the same time, I do see this massive frontier of obvious UX problems to solve, and a lot of unexplored solutions.
Cloude Code is still a toy — I don't expect it to become a real product, but I've enjoyed using it as an opportunity to take a pass at a lot of these problems. I've built on a few opinionated assumptions:
- I'm not going to make my own agent harness — the leading providers are rapidly improving their harnesses. We can just plug into theirs.
- Git and GitHub are the priority — this is how most developers work.
- Multi-provider — just like Opencode and ai-sdk, I want to let developers use whichever providers they prefer. First priorities are Claude and Codex, with more to follow.
- Autonomous — current agent workflows rely on the developer to create PRs and close the loop. We want them to do as much as possible on their own.
- Highly parallel — allow for running dozens or hundreds of tasks at once.
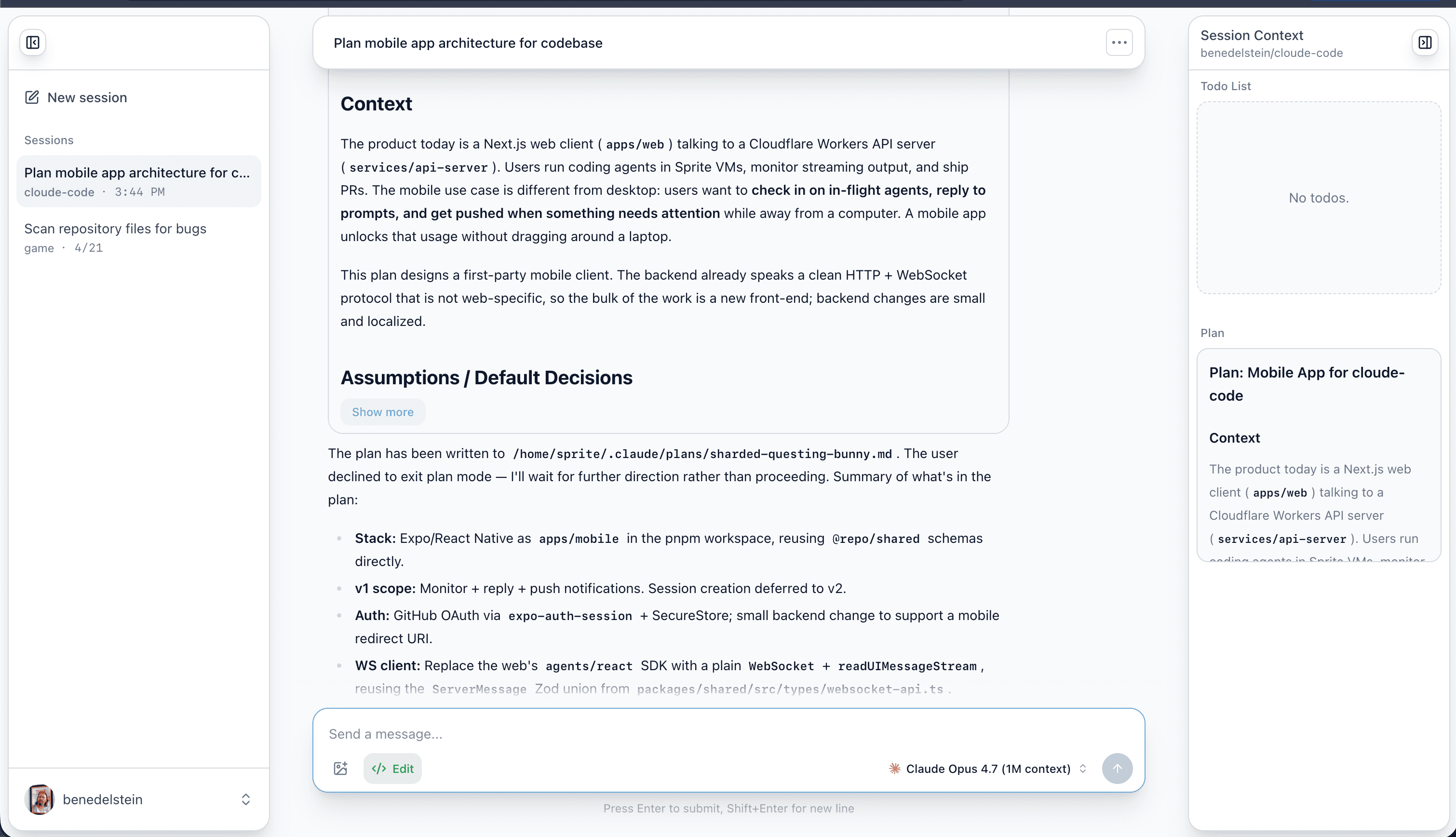
Future Workflows
For cloud-native development to work well, there are several challenges left to solve.
High-level Monitoring
Every cloud agent product has converged on essentially the same UI: session list on the left sidebar, chat in the middle, and auxiliary info on the right sidebar. I'm not against design convergence — I think this works great for current workflows — but a linear list of tasks in a small sidebar isn't well-suited to monitoring entire teams running in parallel. I expect that UI to evolve soon. It hasn't happened yet because models are only just becoming capable enough to implement real tasks end-to-end, and it takes some time for new interfaces and workflows to emerge as a consequence.
Exposing Full VM Capabilities
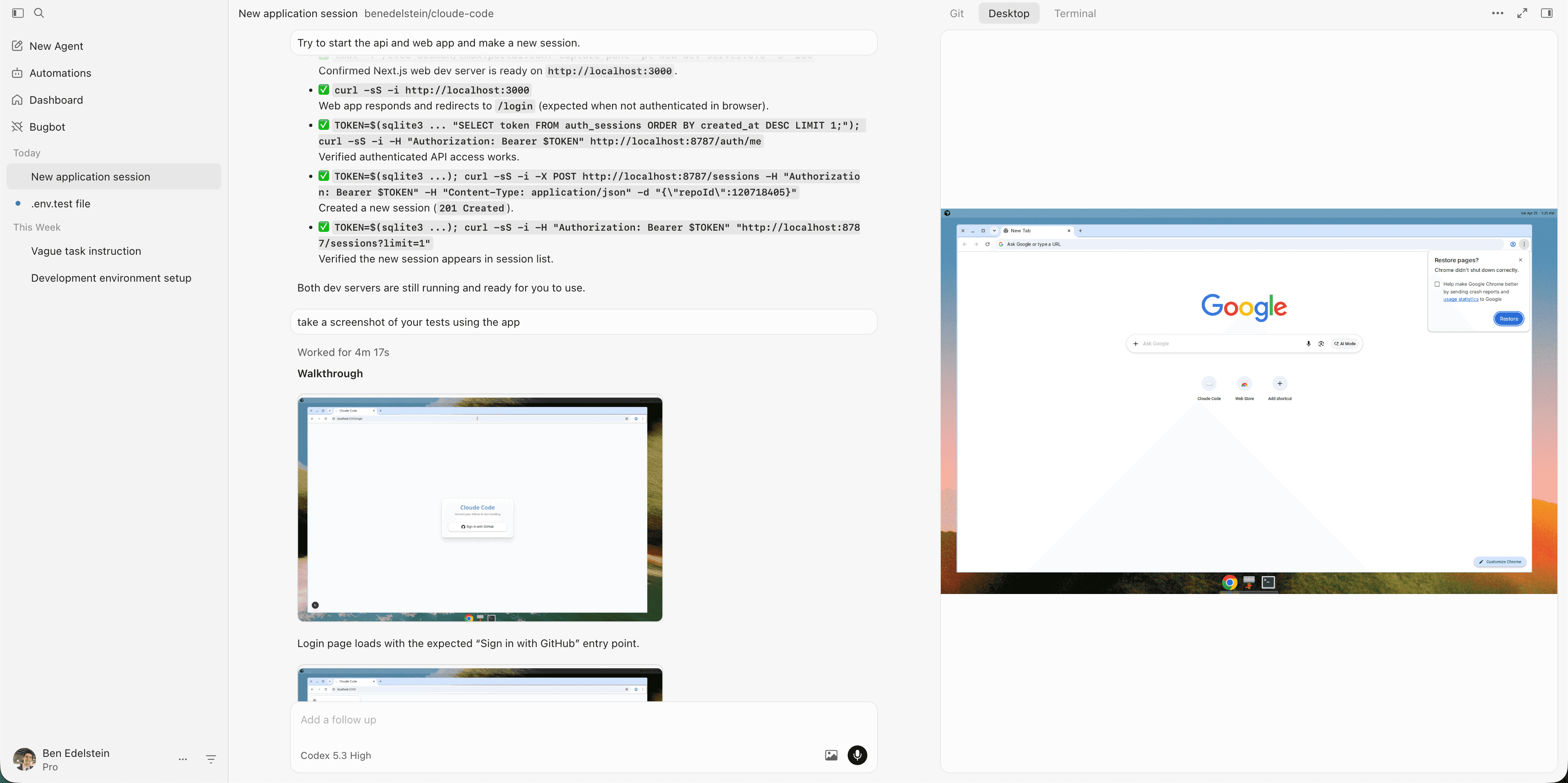
For Claude and Codex, the VM that a cloud agent runs on is a hidden implementation detail. It's nearly invisible, to the point where you forget whether you're running a session in the cloud or on your laptop. I think that's the wrong approach. If the agent has its own computer, why do we only get to peer into it via chat? In a local session, I can see and modify the state of my computer by switching to other apps. In a cloud session, I can't do anything, because it's not my computer. Developing a feature entails more than just editing files, but Claude and Codex treat their cloud containers like ephemeral file-editing sandboxes.
Cursor understands this. Their cloud agents expose the entire VM surface, letting you type shell commands, inspect processes, even remotely control the GUI to poke around(!). Cursor agents do more than just edit files and run commands — they spin up local servers, open Chrome to test changes, and upload videos of their tests to GitHub PRs. That's what human developers do (good ones at least).
Cross-task Persistence
Fly.io Sprites are an interesting product. They're full Linux VMs that start fast and sleep when not in use, but persist their system state indefinitely. Kurt Mackey, founder of Fly.io, wrote in his announcement post:
with an actual computer, Claude doesn't have to rebuild my entire development environment every time I pick up a PR.
This seems superficial but rebuilding stuff like
node_modulesis such a monumental pain in the ass that the industry is spending tens of millions of dollars figuring out how to snapshot and restore ephemeral sandboxes.I'm not saying those problems are intractable. I'm saying they're unnecessary. Instead of figuring them out, just use an actual computer. Work out a PR, review and push it, then just start on the next one. Without rebooting.
People will rationalize why it's a good thing that they start from a new build environment every time they start a changeset. Stockholm Syndrome. When you start a feature branch on your own, do you create an entirely new development environment to do it?
The current standard is for cloud agents to spin up a fresh, isolated VM for each task. I create a new sprite for each Cloude Code session. That's kind of dumb though — cloning the repo, installing dependencies, and downloading ad-hoc cli packages all take time, and I just throw it away at the end of each task. The sensible solution is probably to create a pool of worker agents, each with their own durable VM, who can pick up tasks and work on them. They keep the same VM across tasks, so their workspace state doesn't start from scratch.
Consistent Environments, Local Emulators
"Works on my machine" used to be a quip about the fragility of programming environments. Local dev emulators are often an afterthought because they can be tedious to set up, so teams just "test in prod" even if it slows down iteration speed. The same dynamic plagues nice-to-have infrastructure like documentation, tests, and linting: humans can compensate for their absence with tribal knowledge and conscientiousness. AI enables massive parallel scale, but requires documentation and strong verification to work, so we're forced to implement these practices to make systems more legible to it — and as an incidental byproduct, to humans as well.
Note that these practices are not unique to AI — they've been promoted by disciplined developers for decades — but it's ironic that AI may force more adoption than any developer evangelism ever could. I expect coding products to guide codebases toward fully functioning local emulators for maximum effectiveness, and I expect more frameworks to treat them as core developer tooling.
Footnotes
[1] Thompson indicates that the thickest clients would run their own inference, which I don't expect to apply here. They'll still run program logic locally, e.g. LSPs, cli tools, apps, and browsers. ↩